Wizualizacja danych: najczęstsze błędy. Cz. I
1 minuty czytania
Odpowiednia wizualizacja danych to nie tylko bazowanie na czystych i wiarygodnych danych. Równie ważna jest ich konstrukcja, czytelność i przejrzystość. W tym wpisie przyjrzymy się przykładom takich wykresów i grafik, w których autorom niestety nie udało się oddać poprawnie rzeczywistości, którą opisywali. Ewentualnie zrobili to celowo, dążąc do zmanipulowania odbiorcy.
Najczęściej popełniane błędy lub jak kto woli próby manipulacji podzieliliśmy na kilka obszarów. Przyjrzyjmy się im po kolei.
1. Skala
Dobór skali, która nie zaczyna się od zera powoduje (świadome/celowe lub nie) sztuczne wyolbrzymienie różnic, które w rzeczywistości są duuuużo mniejsze.
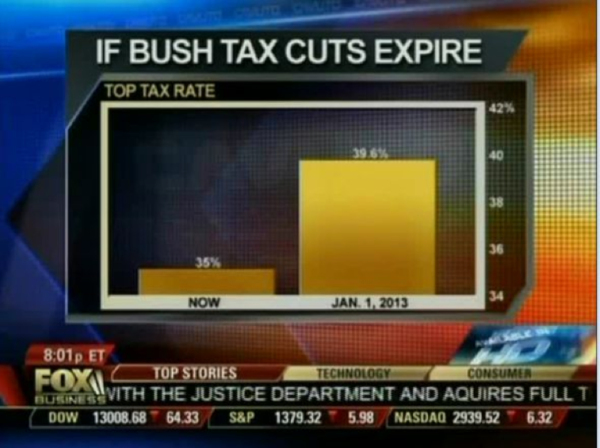
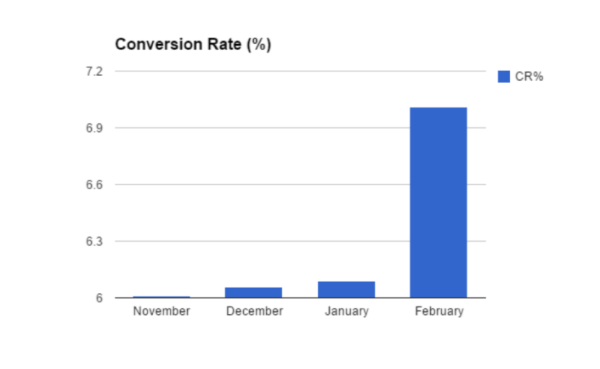
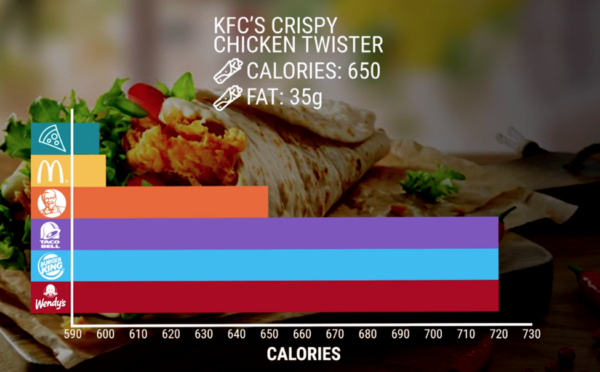
2. Oś Y
Nadmiernie rozciągnięta (lub ściśnięta) skala na osi Y potrafi zdziałać cuda.
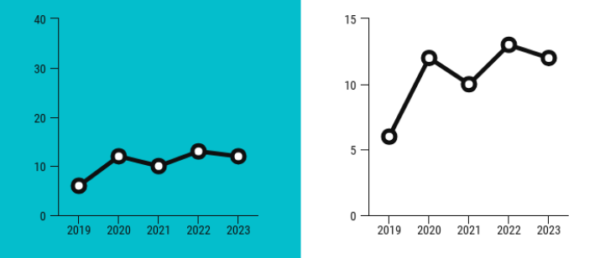
Poniżej przykład wskazujący, że czasem trzeba „odciąć” oś Y powyżej zera. Warto to rozważyć gdy analizie poddana jest jedna zmienna. Pierwszy wykres dotyczący temperatury niewiele nam mówi, ale drugi pozwala już uchwycić trend.
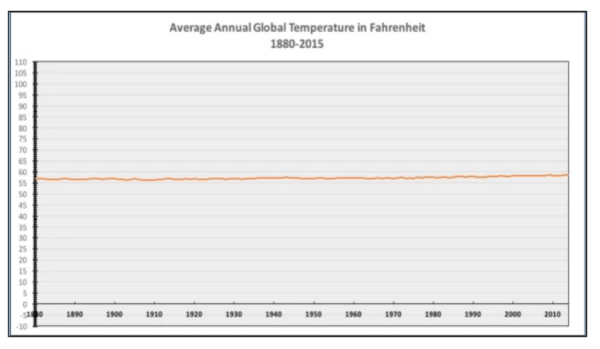
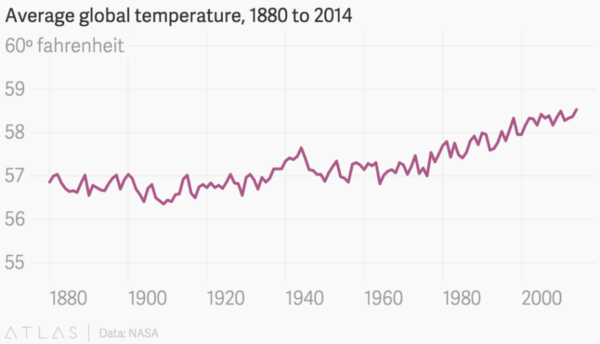
3. Oś X
Błędy lub manipulacje dotyczące osi czasu mogą prowadzić do bardzo mylnej oceny sytuacji.
Pierwszy wykres poniżej niby wygląda OK, ale jest niestety daleko od OK. Na kolejnym wykresie dane źródłowe, które jasno wskazują, że od roku tendencja w zakresie bezrobocia się ustabilizowała.
4. Kolor w mapach
Kolory źle dobrane utrudniają lub uniemożliwiają intuicyjny odbiór map cieplnych. Poniżej dwa przykłady nieczytelne dla odbiorcy. W pierwszym brakuje konsekwencji w stopniowaniu braw, w drugim szwankuje dobór kolorów (pomijamy tu nienajszczęśliwszą kwestię wykorzystania danych bezwzględnych).

Wizualizacja danych będzie jeszcze przedmiotem kolejnego wpisu na naszym blogu. Przyjrzymy się kolejnym przykładom niewłaściwych praktyk m.in. w zakresie perspektywy i jednostek.
Źródła i ciekawe linki:
Related posts
We are increasing company value, for real